Zetaphor@zemmy.cc to LocalLLaMA@sh.itjust.worksEnglish · 10 months agoDistilling step-by-step: Outperforming larger language models with less training data and smaller model sizesblog.research.googleexternal-linkmessage-square1fedilinkarrow-up12arrow-down10
arrow-up12arrow-down1external-linkDistilling step-by-step: Outperforming larger language models with less training data and smaller model sizesblog.research.googleZetaphor@zemmy.cc to LocalLLaMA@sh.itjust.worksEnglish · 10 months agomessage-square1fedilink
minus-squarenoneabove1182@sh.itjust.worksMlinkfedilinkEnglisharrow-up1·10 months agoWoah this is pretty interesting stuff, I wonder how practical it is to do, I don’t see a repo offering a script or anything so may be quite involved but looks promising. Anything to reduce size while maintaining performance is huge at this time


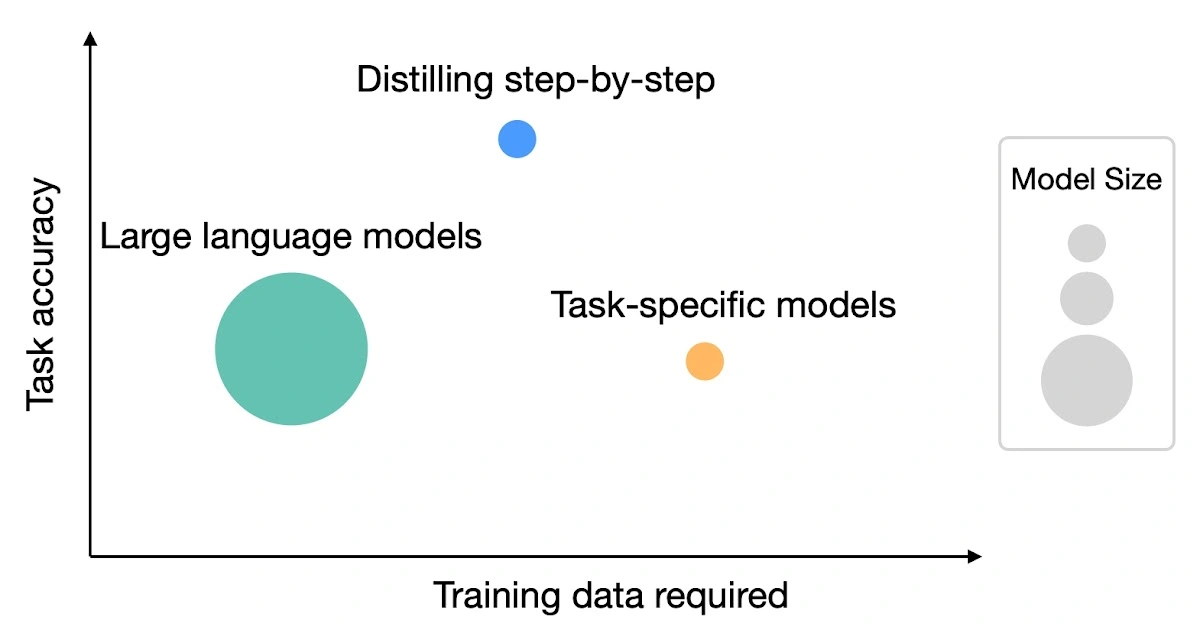
Woah this is pretty interesting stuff, I wonder how practical it is to do, I don’t see a repo offering a script or anything so may be quite involved but looks promising. Anything to reduce size while maintaining performance is huge at this time